| Step | Name | Description |
| IF | Instruction Fetch | fetch instruction, update PC |
| ID | Instruction Decode | fetch registers, decode (generate control signals) |
| EX | Execute | perform ALU operation |
| MEM | Memory Access | read/write memory |
| WB | Write Back | store result in destination register |
The operations required in the IF stage are the same for all instructions: fetch the instruction and update the PC. After the IF stage, the required operations differ.
The label is translated by the assembler into a displacement: the number of statements between the branch statement and the branch target.
| Instruction | Steps Required |
| R type | IF ID EX WB |
| branch | IF ID EX |
| load | IF ID EX MEM WB |
| store | IF ID EX MEM |
To make sure that there is only one instruction in each stage at any given time, the unused stages are filled with no-ops, or doing-nothing's. This makes these instructions take longer but keeps the pipeline running in synch.
| Instruction | Steps Required |
| R type | IF ID EX NOP WB |
| branch | IF ID EX NOP NOP |
| load | IF ID EX MEM WB |
| store | IF ID EX MEM NOP |
Here is an example of a few instructions going through the pipeline:
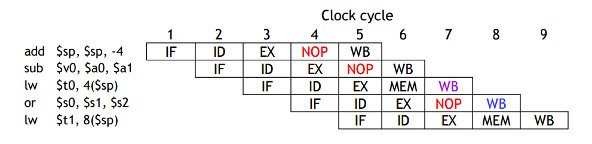
Given:
So the total time for n instructions in a k stage pipeline is:
k*tp + (n-1)*tp = (k+n-1)*tp
The total time without a pipeline for n instructions is n * k*tp. The speedup from pipelining is:
speedup = (time without pipelining) / (time with pipelining)
= n*k*tp / (k+n-1)*tp
For large n, this gets very close to:
n*k*tp / n*tp = k
So theoretically, speedup is the number of stages in the pipeline.
The images in this handout are taken from "Computer Organization and Design" by Patterson and Hennessy.
There are three things that can disrupt the smooth flow of the pipeline:
This problem is solved by duplicating resources that are needed in multiple stages. MIPS has an adder dedicated to updating the PC by adding 4 (used in IF). MIPS also has an adder dedicated to updating the PC with the branch target address (used in EX). This leaves the CPU free to execute the operation required in the EX stage. Also, MIPS has separate memories (caches) for instructions and data, so one instruction can use the instruction memory in the IF stage at the same time that another instruction uses the data memory in the MEM stage.
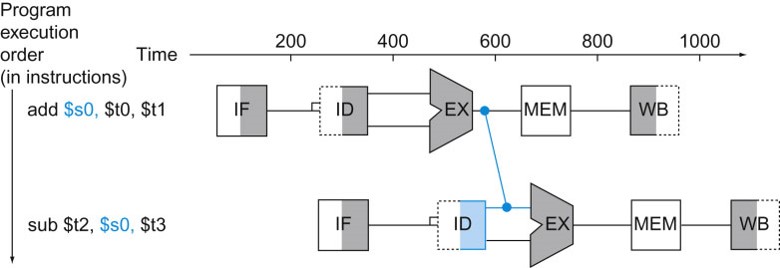
A data hazard occurs when one instruction needs the result of an earlier instruction that is still in the pipeline, for example:
add $s0, $t0, $t1 sub $t2, $s0, $t3
This is called a data dependency. Since the add instruction doesn't update $s0 until the WB stage, this could stall (delay) the pipeline for three cycles. Data dependencies occur in our code all the time. One way to avoid this hazard is to have the compiler reorder the statements to remove the dependency. This is often not possible, so it's not enough.
As soon as the ALU computes the result of the add, it can be sent directly to the input of the sub. This is an example of forwarding or bypassing, which is the main solution to data hazards. This requires extra hardware to send the output of the ALU (from the add) to the input of the ALU (for the sub). In our example, this will remove the pipeline delay.
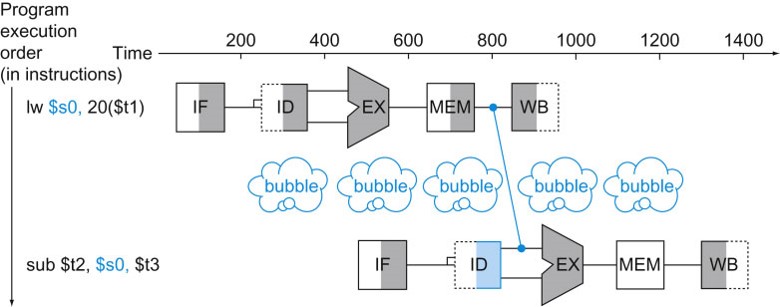
However, if we have a load followed by an R-type instruction:
lw $s0, 4($t1) sub $t2, $s0, $t3
the result of the load is not available until after the MEM stage. Forwarding will help but will not eliminate the delay, so a stall (also called a bubble) is still needed:
The statement after a branch has to be fetched right after the branch is fetched. But there is no way to know which instruction should be fetched, because the branch condition hasn't been evaluated yet. This control hazard occurs on every branch instruction. There are several ways to handle it:
add $4, $5, $6
beq $1, $2, labela
or $7, $8, $9
These instructions can be reordered as follows:
beq $1, $2, labela
add $4, $5, $6
or $7, $8, $9
The branch instruction is completed in time to load either
the or instruction or the instruction at labela.The images in this handout are taken from "Computer Organization and Design" by Patterson and Hennessy.
Email Me |
Office Hours |
My Home Page |
Department Home |
MCC Home Page
© Copyright Emmi Schatz 2017